Introduction
Arthur Samuel, a pioneer in the field of computer gaming and artificial intelligence, described machine learning as a field of study that gives computers the ability to learn without being explicitly programmed. ML is being increasingly utilized for a variety of applications from recommending new movies to programming self-driving cars. Furthermore, owing to it’s breakthrough in computer vision, speech recognition, ads, social feed and auto-complete etc, Deep Learning (DL) has gained huge attention and has helped the human race in many re- spects. With the advancement in technology, we can extend the embedment of these sophisticated applications into mobile devices and computers, with which individuals spend most of their time. Our activities like search queries, purchase transactions, the videos we watch, and our movie preferences are the few types of information that are being collected and stored on regular basis at both local(search engine) and remote storage(service enabled servers) for further processing. Our personal data generated through these activities are used by ML applications to give us better user-experience. Such private data is uploaded to centralized locations in clear text for ML algorithms which in-turn extract patterns from them, and update models accordingly(federated learning). The sensitivity of such data increases it’s risk of being maliciously used by an insider as well as outsider. Additionally, it is possible to gain insights into private data sets even if these data are anonymized and the ML models are inaccessible. A machine learning process consists of two phases viz. training phase and evaluation phase. In the learn- ing phase, a model or classifier is built on a possibly large data set. In the second phase, the trained model is being queried and based on its result, it is further updated for better accuracy in the next time-step. For every ML task, three different roles are possible: the input party (data owners or contributors), the computation party and the result party. In such systems, the data owner(s) send their data to the computation party which perform the required ML task and deliver the output to the result party. Such output could be an ML model that the result party can utilize for testing new samples. In other cases, the computation party might keep the ML model, and perform the task of testing new samples submitted by the result party, and returning the test results to the result party. If all the three roles are played by the same entity, then privacy is naturally pre- served, however when these roles are distributed across two or more entities, then PRIVACY-ENHANCING TECHNOLOGIES are needed.
Review of Data Privacy in 2018-19:-
2018 was a breakout year for privacy-preserving machine learning(PPML). This year’s news cycle had several major stories surface around data privacy, which makes it the most relevant year for privacy since the Snowden leaks in 2013. Data Privacy impacts our politics, security, businesses, relationships, health, and finances.
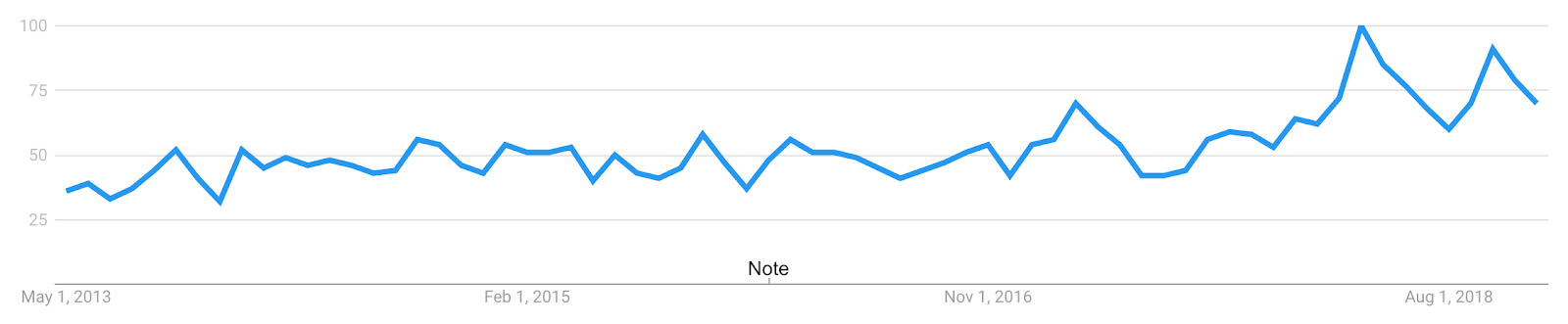
Figure 1: Google Trends for “data privacy”, 2013 — 2019
ML-as-a-Service(MLaaS)
In this technology-driven world, most of the organizations have deployed their ML and DL based trained models into the cloud for better reliability and integrity. For a particular query from Data owners, they are both Computation Party and Results’ Party and this can affect the overall privacy of owners adversely. In fact, with all of the data that is collected from individuals around the world on daily basis, data owners might not be aware of how the data collected from them is being used (or misused), and in many cases, not even aware that some data types are being collected.
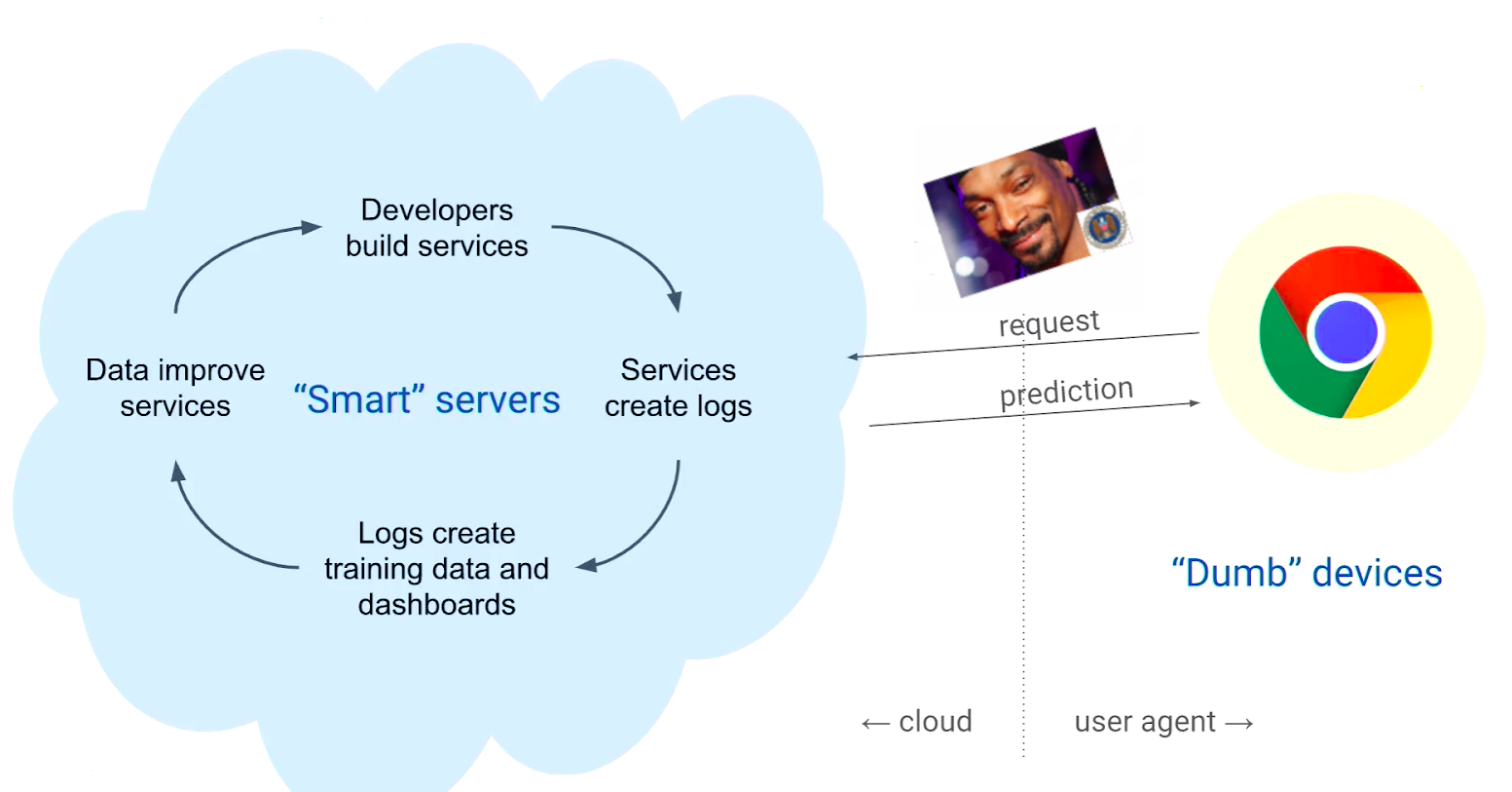
Figure 2: Most Machine learning today is done in the cloud
Why we need privacy in ML algorithms as they already involve complex mathematics-which makes decoding hard?
About 2 years ago, Google researchers introduced a Skin disease classifier at the global level. They developed an application to take photos of skin, and run it to CNN(Convolutional Neural Network) to intimate about your visit to a dermatologist. It was also observed that the accuracy of prediction was an expert level. When the user queries the application, they do not make any changes(e.g. noise perturbation) to the input skin image. The service provided then takes it for further processing.
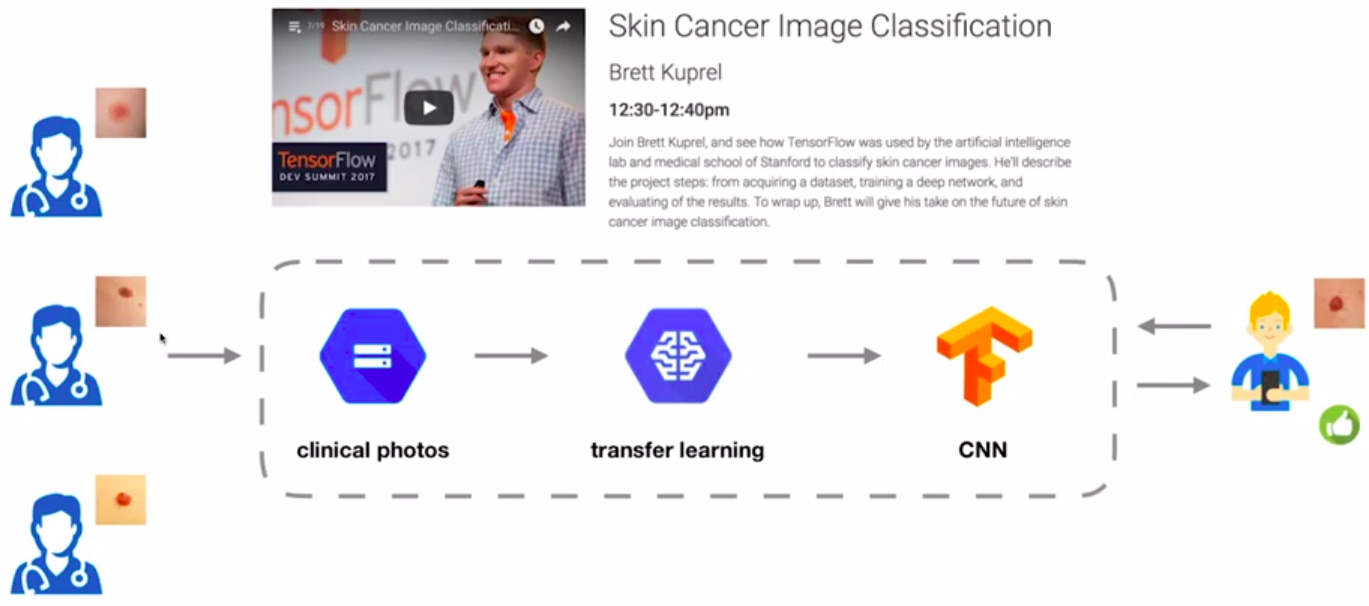
Figure 3: Skin Cancer Classifier
The same uploaded skin image may contain sensitive information about an individual. The results of this information leakage could be harmful in some cases.
Under such circumstances, the ML service could potentially become unreliable. Therefore, we need privacy at both the input and output ends when we don’t have access
to the model.
Note: This is one of the example on top of my head now. There are hundreds of others also, which directs affects user privacy.
Some threats with Machine Learning
-
Membership Inference Attack
Given an ML model and a sample (adversary’s knowledge), membership inference attacks aim to determine if the sample was a member of the training set used to build this ML model (adversary’s target). This attack could be used by an adversary to learn whether a certain individual’s record was used to train an ML model associated with a specific disease. Such attacks utilize the differences in the ML model predictions on samples that were used in the training set versus those that were not included.
-
De-anonymisation Attacks (Re-Identification)
Identification of the target sample from the anonymized dataset. Example: Usage of IMDB background knowledge to identify the Netflix records of known users.This incident demonstrates that anonymization cannot reliably protect the privacy of individuals in the face of strong adversaries.
-
Model Inversion Attack
Some ML algorithms produce models where explicit feature vectors are not stored in the ML model, E.g. ridge regression or neural networks. Hence, the adversary’s knowledge would be limited to either: (a) an ML model with no stored feature vectors (whitebox access), or (b) only the responses returned by the computation party when the results’ party submits new testing samples (black-box access). Here, the adversary’s target is creating feature vectors that resemble those used to create an ML model by utilizing the responses received from that ML model.
-
Re-Construction Attack
In this case, the adversary’s goal is reconstructing the raw private data by using their knowledge of the feature vectors. Reconstruction attacks require white-box access to the ML model, i.e. the feature vectors in a model must be known. Such attacks could be possible when the feature vectors used for the ML training phase were not deleted after building the desired ML model. In fact, some ML algorithms such as SVM or kNN store feature vectors in the model itself.).The final aim of these attacks is to misguide a ML system into thinking the reconstructed raw data belonged to a certain data owner. Example: Fingerprint reconstruction, Mobile device touch gesture reconstruction.
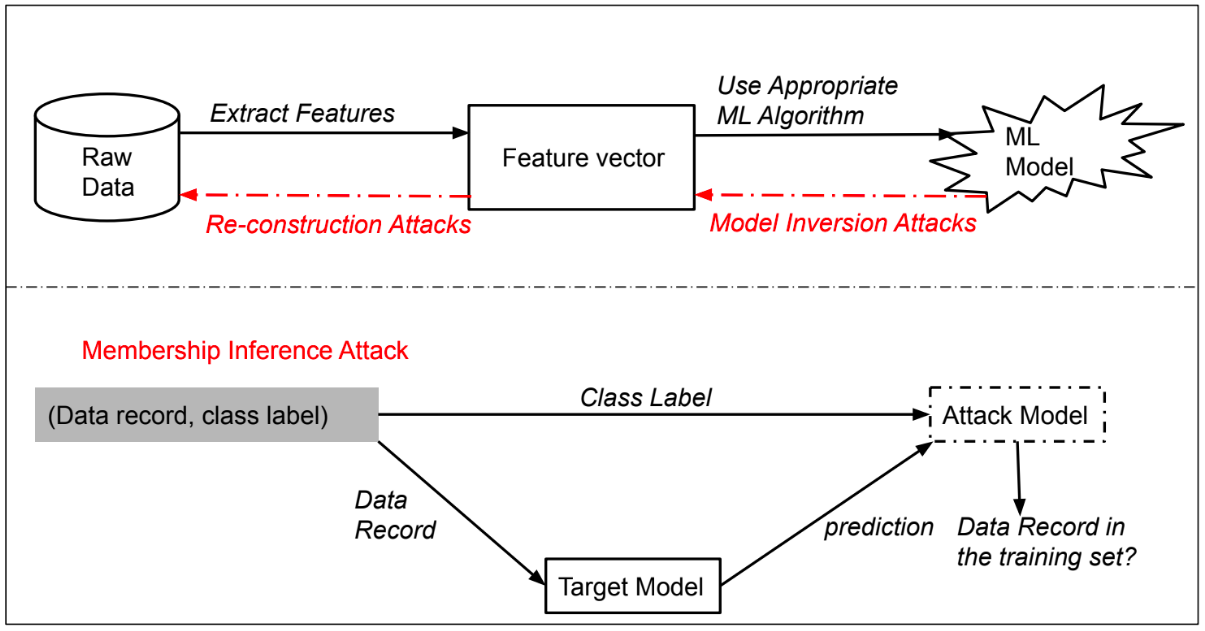
Figure 4: Threats with ML Models
Some methods for Private ML
- Cryptographic approaches:
When a certain ML application requires data from multiple input parties,
cryptographic protocols could be utilized to perform ML training/testing on encrypted data. In many of
these techniques, achieving better efficiency involved having data owners contribute their encrypted data
to the computation servers.It can also be seen by training the model on cipher-text.
- Homomorphic encryption
- Secure Multiparty Computation(Secret sharing)
- Garbled circuits etc.
- Perturbation techniques:
Feeding updated data by adding noise to the actual raw data, which results into similar output as before
without revealing anything about actual information.
- Differential Privacy
- Data Owners’ i.e. Input perturbation
- Computational Party i.e. Algorithmic perturbation
- Results’ Party i.e .Output perturbation
- Dimensional reduction
- Differential Privacy