Federated Learning from adversarial view
Background and Rationale
Mobile phones, wearable devices, voice assistants, and autonomous vehicles are just a few of the new distributed networks generating a wealth of data each day, where each data sample belongs to different type of statistical distribution(Non- IID’s) . Due to the growing computational power of these devices—coupled with concerns about transmitting private information(if it gets leaked, a lot about the device and the user’s behavior can be inferred easily)—it is increasingly attractive to store data locally and thus, push network computation closer to the edge devices. The learning becomes more challenging as it seems if data contains sensitive information like location, health, and other ambient signals because the private information gets more sensitive over time, which may lead to bad user experience. Federated learning has emerged as a new training paradigm in such settings. Federated learning (aka collaborative learning) is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging their data samples. It stands in contrast to traditional centralized machine learning techniques where all data samples are uploaded to one server, as well as to more classical decentralized approaches which assume that local data samples are identically distributed. From [1], FL is privacy-preserving model training in heterogeneous,distributed networks.
FL Applications
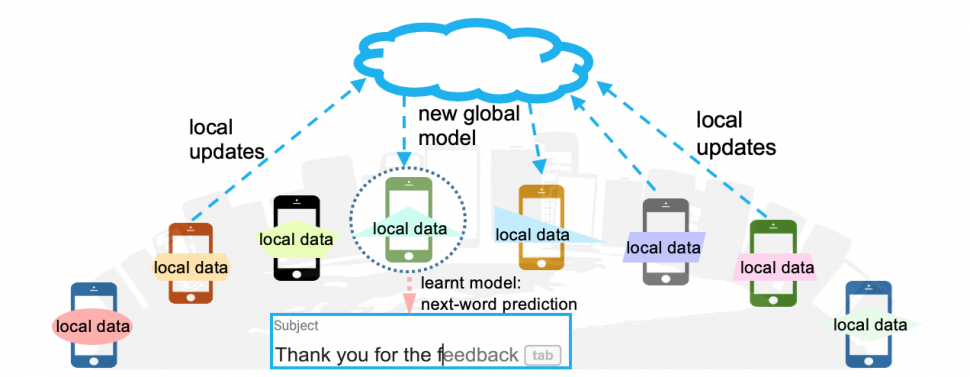
Auto-suggestion application
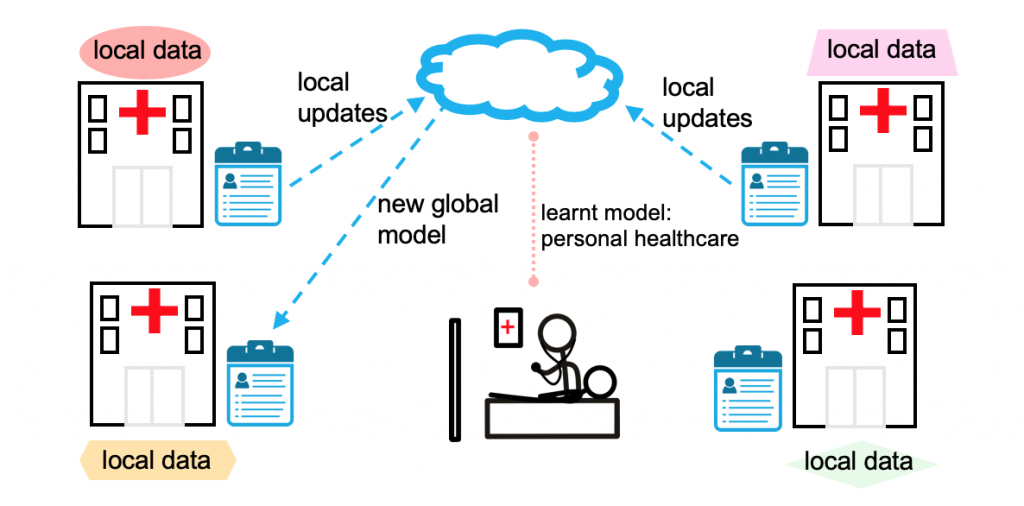
Usage of federated learning for providing better healthcare by taking relevant data from various medical organisations, which in turn is difficult to achieve through centralised learning.
Standard Federated Training Algorithm :-
Step I. The master device sends the current global model parameters to all worker devices.
Step II. The worker devices update their local model parameters using the current global model parameters and their local training datasets in parallel. In particular, each worker device essentially aims to solve the loss function using the stochastic gradient descent. Note that a worker device could apply SGD multiple rounds to update its local model. After updating the local models, the worker devices send them to the master device.
Step III. The master device aggregates the local models from the worker devices to obtain a new global model according to a certain aggregation rule. REPEAT STEP I.
Some literature review about attacks on FL
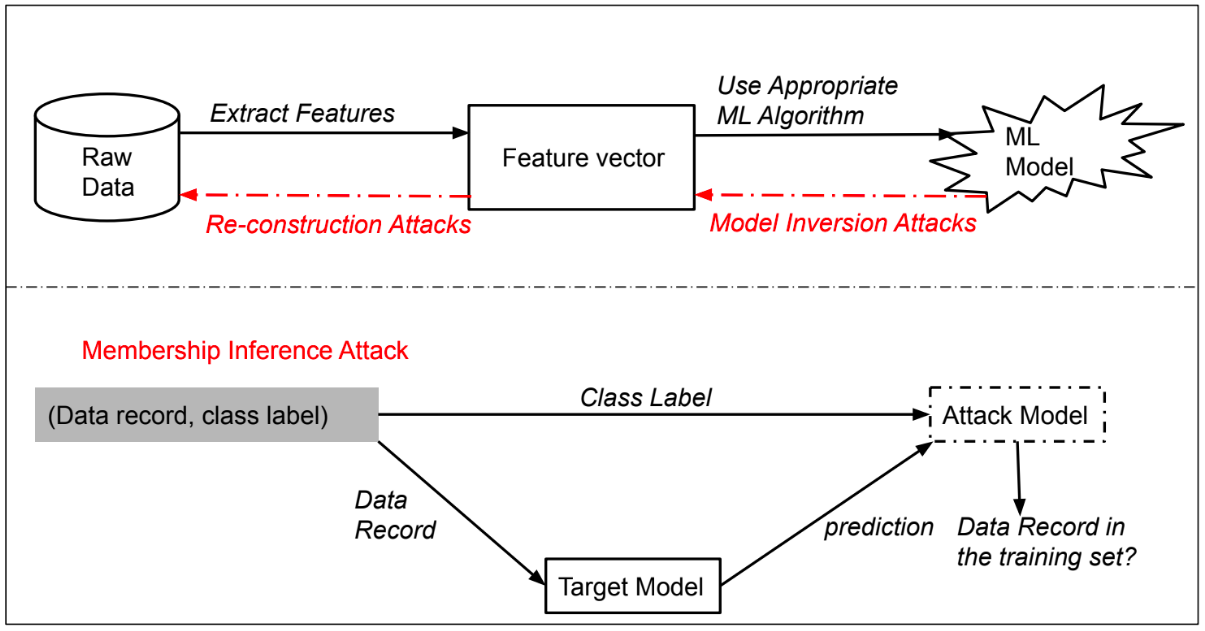
If we see the federated training algorithm closely, in all the three steps, the data of each individual is not being used directly, which motivates the participating users to share their sensitive data for useful learning. At first glance, it also provides some privacy guarantee as the raw data never leaves the user device, and only updates to models (e.g., gradient updates) are sent to the central server, which is not in the case of a centralized setting. On the contrary, recent works by Shokri et al [4] have shown that it is possible to construct scenarios in which information about the raw data is leaked from a client to the server, such as a scenario where knowing the previous model and the gradient update from a user would allow one to infer a training example held by that user which is popularly known as Membership-Inference attack among ML community.
To provide better user privacy, several cryptographic and data perturbation techniques like Homomorphic Encryption, Secure-Multi Party Computation, and Differential Privacy(or any combination of them) are proposed, which do provide a reliable theoretical privacy guarantee. Bargav et al. [3] presented a better lower bound in Differential Privacy as compared to other state-of-art bounds by perturbing the gradient at MPC i.e., aggregation side instead of adding noise at user level for Logistic regression. However the work didn’t show any bounds for Deep learning algorithms which are mostly used in various learning tasks now-a-days. Bargav et al. [2] also shows the evaluation of the different versions of DP like Naive DP, Renyi DP, etc. on several well-known datasets trained using both traditional ML and Neural Networks algorithms and found out privacy loss is directly proportional to number of epochs. The Secure Aggregation protocol from McMahan et al. [5] has strong privacy guarantees when aggregating client updates. Moreover, the protocol is tailored to the setting of federated learning. For example, it is robust to clients dropping out during the execution (a common feature of cross-device FL) and scales to a large number of parties and vector lengths. However, this approach has several limitations: (a) it assumes a semi-honest server (only in the private key infrastructure phase), (b) it allows the server to see the per-round aggregates (which may still leak information), (c) it is not efficient for sparse vector aggregation, and (d) it lacks the ability to enforce well-formedness of client inputs. Furthermore [1] , also provides the concept of FHE, which suits better in case of heavy computational edge devices, but fails miserably where end devices are Mobile phones or IOT devices, which of-course is the case of federated learning.
In the distributed datacenter and centralized settings, there has been a wide variety of work concerning attacks and defenses for various targetted and untargetted attacks, namely through model update poisoning, data poisoning. for example, (an adversary might attempt to prevent a model from being learned at all). In these attacks, the adversary(or adversaries) directly control some number of clients, and thus, they can directly manipulate reports to service provider to alter the outputs to bias the learned model towards their objective. They may also be able to tailor their output to have similar variance and magnitude as the correct model updates, making them difficut to detect. For this, several Byzantine-Resilient Defense mechanisms were proposed by machine learning and Blockchain community, one of them is to replace the averaging step on the server with median-based agreegators. Fang et al. [7] performs successful local model poisoing attacks, which can substantially increase the error rates of the models learnt through federated learning that were claimed to be robust against Byzantine failures of some client devices.
Relationship between model update poisoning and data poisoning
Intuitively, the relation between model update poisoning and data poisoning should depend on the over-parameterization of the model with respect to the data. The study by Fang et al. [6] proposes two methods to defend against local model poisoning attacks. Their results clearly show that only in some cases, one out of two methods can effectively defend these attacks and it also make the global model slower to learn and adapt to new data as that data may be identified as from potentially malicious local models. Thus, the proposed defenses are not effective enough for every case, highlighting the need for new defenses against model poisoning attacks to federated learning. Existing defenses against backdoor attacks either require a careful examination of the training data, or full control of the training process at the server (as happens in centralised setting), none of which may hold in the federated learning setting. The property of Zero-knowledge proof can be used to ensure that users are submitting updates with pre-decided protocol. One interesting line of study would be to quantify the gap between these two types of attacks, and relate this gap to the relative strength of an adversary operating under these attack models. For example, the maximum number of clients that can perform data poisoning attacks may be much higher than the number that can perform model update poisoning attacks, especially in cross-device settings. Thus, understanding the relation between these two attack types, especially as they relate to the number of adversarial clients, would greatly help our understanding of the threat landscape in federated learning.
Motivation while writing this post
I had the following motivations while writing this post:-
Given n, no. of working devices and an honest
but curious Server, Formulation of an innovative protocol which can provide rigorous privacy guarantees in the following scenarios:-
- When m out of n clients become adversaries or an adversary controls m clients in the cross-device or cross-silo federated setting, aiming to perform various attacks such as Data Poisoning, Model UpdatePoisoning, and Backdoor attacks.
- Robustness of the same developed protocol towards federated training algorithm, when a certain number of trusted users drop out due to participation constraints, ending up in a network having more number of malicious clients.
References
- David Evans, Rachel Cummings, Martin Jaggi et al . Advances and Open problems in Federated Learning. arXiv:1912.04977
- Bargav Jayaraman and David Evans. Evaluating Differentially Private Machine Learning in Practice. In 28th USENIX Security Symposium 2019.
- Bargav Jayaraman, Lingxiao Wang, David Evans, and Quanquan Gu. Distributed Learning without Distress: Privacy-Preserving Empirical Risk Minimization. 32nd Conference on Neural Information Processing Systems (NeurIPS 2018).
- Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership Inference Attacks Against Machine Learning Models. IEEE Symposium on Security and Privacy (S\&P) – Oakland, 2017.
- Keith Bonawitz, H. Brendan McMahan, et al. (@Google), and Antonio Marcedone(@Cornell tech) . Practical Secure Aggregation for Privacy-Preserving Machine Learning. arXiv:1611.04482.
- Minghong Fang, Xiaoyu Cao, Jinyuan Jia, and Neil Zhenqiang Gomg. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. Usenix Security Symposium,2020.